Unlocking Hair Restoration: A Journey to Fuller Hair
Discover the ultimate guide to hair restoration, unlocking the secrets of hair transplants and redefining your confidence journey.
Welcome to the fascinating world of hair transplants, where science meets art to give you a renewed sense of confidence and style. This journey to fuller hair is meticulously catered to individuals seeking a permanent solution to hair loss issues. By integrating modern techniques with expert care, hair restoration has become a symbol of rejuvenation and self-assurance. Discover the stages of hair restoration, from identifying the root causes of hair loss to exploring cutting-edge transplant techniques.
Understanding Hair Loss: Identifying the Root Causes
Unveiling the Genetic Predisposition to Hair Loss
Genetics often sets the stage for hair loss, making it a primary determinant, especially in cases of androgenic alopecia. If your family tree includes individuals with baldness, you might find yourself at a higher risk. This predisposition doesn't guarantee hair loss but increases susceptibility, indicating a need for proactive hair care. Understanding your genetic background can empower you to take preventive measures early on.
- Family History Analysis: Assess if baldness is prevalent among first-degree relatives to gauge your risk level.
- Genetic Testing: Consider genetic tests that can identify specific genes linked to hair loss, allowing for informed decisions.
- Early Intervention: If genetics point to a higher risk, consult with professionals for proactive management strategies.
For instance, men with a strong paternal history of baldness might start preventative treatments like Minoxidil earlier, while those with a maternal history might focus on hormonal balance. Remember, while genetics play a significant role, they don't act in isolation; lifestyle and environmental factors also contribute.
Lifestyle Factors and Their Impact on Hair Health
Lifestyle choices can significantly influence hair health, often exacerbating genetic predispositions or hormonal imbalances. Stress, poor diet, and lack of exercise can all contribute to hair thinning and hair loss. Managing stress levels through mindfulness or yoga can mitigate its impact on hair health. A balanced diet rich in vitamins and minerals, especially iron and zinc, nourishes hair follicles from within.
- Dietary Adjustments: Focus on a balanced intake, incorporating iron, zinc, and vitamins to support hair follicle health.
- Stress Management: Practice mindfulness or yoga to lower stress hormones linked to hair loss, enhancing overall well-being.
- Regular Exercise: Physical activity boosts circulation, ensuring hair follicles receive adequate nutrients and oxygen.
For example, someone experiencing hair loss might benefit from adding iron-rich foods like spinach to their diet or introducing stress-reducing activities like meditation. Addressing lifestyle factors is not just about delaying hair loss; it's about promoting overall health and well-being. Embarking on a Hair Today, Hope Tomorrow: Your Hair Transplant Journey Starts Now can sometimes also mean changing your daily routine.

Hair Transplant Techniques: FUE, FUT, and Scalp Micropigmentation Explained
Comparing FUE and FUT: Minimally Invasive vs. Maximum Graft Count
Follicular Unit Extraction (FUE) and Follicular Unit Transplantation (FUT) stand as primary choices in surgical hair restoration, each presenting distinct advantages. FUE is favored for its minimally invasive nature, extracting individual hair follicles, which results in tiny, virtually undetectable scars. FUT, conversely, involves removing a strip of scalp, allowing for a higher yield of grafts in a single session. The choice between FUE and FUT often depends on the patient’s specific needs, hair loss extent, and preference for scarring versus graft quantity.
- Scarring: FUE leaves minimal dot-like scars, while FUT results in a single linear scar.
- Graft Quantity: FUT typically allows for a larger number of grafts to be transplanted in one session.
- Recovery: FUE generally has a faster recovery period compared to FUT due to its less invasive nature.
For instance, someone seeking to conceal the signs of hair restoration quickly might opt for FUE, while another needing extensive coverage in one go may lean towards FUT. Understanding these nuances is crucial when exploring your Hair Today, Hope Tomorrow: Your Hair Transplant Journey Starts Now and selecting the right avenue.
The Art of Illusion: Understanding Scalp Micropigmentation
Scalp micropigmentation (SMP) offers a non-surgical solution to hair loss by creating the illusion of a fuller head of hair. This technique involves using micro-needles to deposit pigment into the scalp, mimicking the appearance of hair follicles. SMP is particularly suitable for those with extensive hair loss, those unsuitable for surgery, or those seeking to camouflage scars from previous hair transplant procedures. The result is a natural-looking, low-maintenance alternative to traditional hair restoration methods. Worldwide, over 100,000 people opt for SMP each year as a safe and effective solution for hair loss.
- Non-Surgical: SMP is a non-invasive option, avoiding the need for surgical procedures.
- Camouflage: It effectively camouflages scars, making it an ideal choice post-surgery.
- Low Maintenance: SMP requires minimal upkeep, fitting well into a busy lifestyle.
For example, a celebrity seeking to maintain a youthful appearance without undergoing surgery might choose SMP, or someone with a visible FUT scar could use SMP to blend it seamlessly with the surrounding hair. Scalp micropigmentation provides an immediate aesthetic improvement, boosting confidence and enhancing overall appearance.
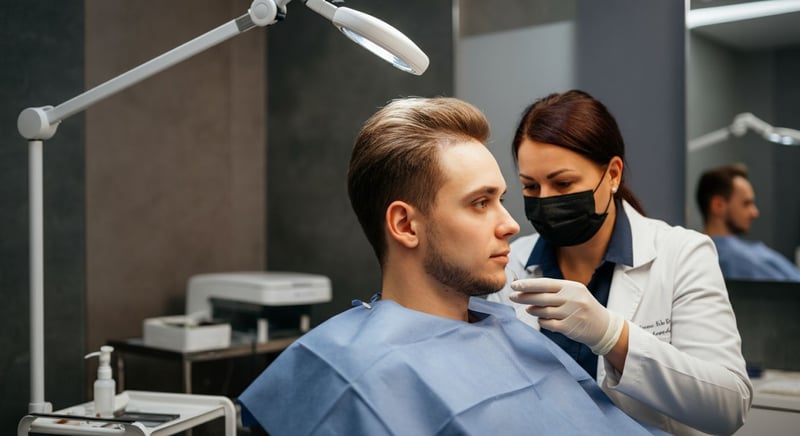
Navigating the Hair Transplant Recovery Timeline: What to Expect
Short and Long-Term Expectations After a Hair Transplant
After undergoing a hair transplant, understanding the recovery timeline is essential for managing expectations and ensuring the best possible results. Immediately post-procedure, it's common to experience some swelling and discomfort, which typically subsides within a few days with prescribed medication. The initial weeks often bring about "shock loss," where transplanted hairs fall out, making it crucial to understand this is a normal part of the process. Hair regrowth typically begins around the third month, with progressively noticeable improvements seen by the sixth month.
- Immediate Post-Op: Manage swelling and discomfort with prescribed medication.
- Shock Loss Phase: Expect temporary hair shedding in the initial weeks, followed by new growth.
- Mid-Term Growth: Hair regrowth starts around month three, with visible improvements by month six.
For example, patients may notice the initial shedding and become concerned, but understanding this is normal eases anxiety. By the sixth month, many see significant aesthetic improvements, like a fuller hairline or increased density where hair was thinning. Esthetica Global emphasizes patient education to ensure they are well-prepared for each stage.
Managing the Recovery Budget
Embarking on a hair transplant journey involves more than just the procedure itself; it includes planning for the recovery period. While Esthetica Global does not offer specific pricing, it's important to consider factors like aftercare products and follow-up consultations into your overall budget. The cost of these components can vary, but they are crucial for optimal results. Patients should discuss potential expenses with the clinic to avoid surprises.
- Plan Ahead: Account for post-operative care items necessary for healing.
- Consultations: Factor in the cost of follow-up appointments to monitor progress.
- Flexibility: Be ready for potential minor aesthetic corrections.
For instance, some patients might require special shampoos or serums to encourage hair growth and reduce inflammation, while others may need additional sessions to refine the hairline. Preparing for these possibilities ensures a smooth and successful hair restoration process with Esthetica Global.
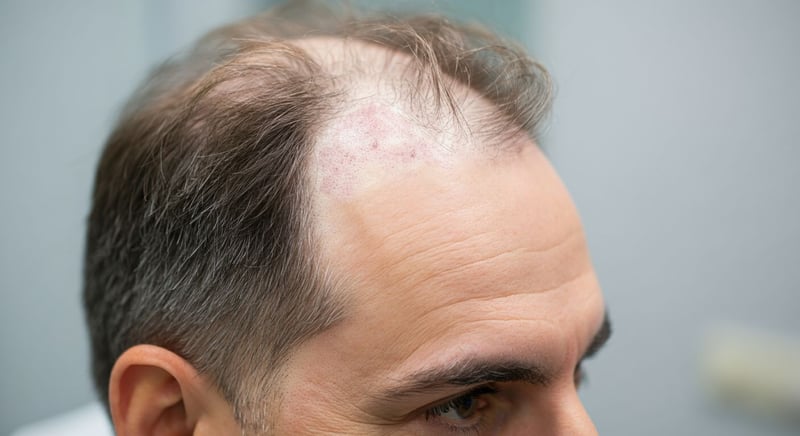
Beyond the Procedure: Long-Term Hair Loss Treatment and Maintenance
Sustaining Your Investment: The Ongoing Care Regimen
Achieving a successful hair transplant with Esthetica Global is a significant step, but it marks the beginning of a sustained hair care journey. Consistent maintenance is crucial for preserving the density and vitality of your transplanted hair. This involves regular scalp care, specialized hair products, and potentially supplementary treatments. Think of it as nurturing a garden; the initial planting is important, but ongoing care ensures long-term growth. By prioritizing continuous care, you protect your investment and enjoy lasting results. Many individuals find adapting these practices into their daily routines ensures the continued health of their hair.
- Specialized Shampoos and Conditioners: Use products designed for post-transplant care to maintain scalp health and encourage hair growth.
- PRP Therapy: Explore Platelet-Rich Plasma therapy to promote healing and stimulate hair growth with your body's growth factors.
- Consistent Follow-Ups: Schedule regular consultations with your hair specialist to address any emerging issues promptly.
Enhancing Longevity: Lifestyle Factors and Follow-Up Care
Lifestyle choices significantly impact the long-term success of a hair transplant. A nutrient-rich diet, stress reduction techniques, and avoidance of harsh chemicals can all contribute to healthier hair. The impact is similar to providing the right building blocks for hair follicles to thrive. Furthermore, consistent follow-up consultations with your hair specialist are vital. These appointments allow for early detection of potential issues and adjustments to your hair care routine. By actively participating in your hair's health, you maximize the durability of your hair restoration, solidifying your investment with Esthetica Global. One approach is to actively engage with healthcare professionals and to seek guidance on optimizing your regimen.
- Improve Your Diet: Focus on foods rich in vitamins and minerals to nourish hair follicles from within, supporting stronger hair growth.
- Reduce Stress: Practice relaxation techniques like meditation to minimize stress-related hair thinning and promote overall wellness.
- Attend Regular Consultations: Keep scheduled appointments with your hair specialist for personalized advice and timely interventions.
Advanced FUE and FUT Techniques for Natural-Looking Hair Restoration
Comprehensive Post-Transplant Care and Long-Term Maintenance for Sustained Hair Health
Frequently Asked Questions
What are the primary causes of hair loss that can be addressed with a Hair Transplant?
What are the main differences between FUE and FUT Hair Transplant techniques?
What can I expect during the Hair Transplant recovery timeline?
What is Scalp Micropigmentation, and how does it differ from a Hair Transplant?
What long-term maintenance is required after undergoing a Hair Restoration procedure?
Achieve your aesthetic goals with estethica's world-class services and personalized treatment plans.
📞 Book Your FREE Consultation!